Below are the initial 2017 MLS season forecasts using data from games through February 28, 2017.
What remains the same
This system uses a model to predict the probability of various outcomes of matches, and then uses a large amount of simulations (10,000-20,000 depending on my computing power and the needs at the time) to account for luck.
For example, the model expects Sunday’s match against Vancouver to give the Union a 25.7% chance of winning, a 30.4% chance of a draw, and a 44.0% chance of a loss. Within each simulation, we randomly select any fractional number between 0 and 1. If it lies within the first .257, it is marked as a win, within the next .304, a draw, and within the final .44, it is a loss. By using a large number of simulations, we can best account for the luck inherent in these probability distributions.
Just as last year, we simulate the MLS season & playoffs, USOC, and other MLS-adjacent information. When ready this year, we will also add the USL and NWSL (as with last year) forecasts.
The primary purpose of the system is to put into context the consequences of a match outcome. This system does not tend to make bold choices when the evidence of a variable’s influence is mixed (such as team-specific-expectations). This was particularly noticeable at the end of last season, as the Union backed into the playoffs. Two matches out from the end of the regular season, I was reading all kinds of negative predictions about missing the playoffs, but the SEBA projection system still had the Union with a 96.3% chance of making the playoffs… for a system that does not make bold predictions. The reason, as we all witnessed, was that even if Philadelphia played extremely poorly (as they did), there were already too few pathways to prevent the Union from the playoffs with any likelihood.
Additionally, as with last year, the early-season forecasts largely rely upon last season’s data to base predictions upon. Therefore, the code producing these forecasts is manually constrained to force less-confident predictions (unless there is an abundance of evidence with regards to a variable’s influence, such as with home field advantage). This is why the forecasts currently show all teams extremely close, to reflect our uncertainty with the predictive power of last season’s data.
What changed from last year
For those who may have followed these posts last year, there are a few changes to the underlying model that governs these simulations.
The first is that all matches within the season are no longer treated as equally weighted. Therefore, as the model re-learns the probability distributions it expects, it places less emphasis about accurately understanding older matches than it does about understanding the newer matches. This may seem obvious to many, but I excluded it last year because too often humans turn small patterns of data into concrete conclusions, and I believe that too much reliance upon recent matches can tend to trick us into confusing luck with skill. Nonetheless, I do believe it was incorrect to assume, over such a long season, that early matches are representative of a team’s form at the end.
The second change is borrowed from a newer version of SEBA’s international forecast system. The use of goal differential as a proxy for certainty of victory. Goal differential was always used in forecasting a season, but it is now used to distinguish complete victories from lucky ones. How this works is that if the Philadelphia Union beat one team 3-0 and another 1-0, the model’s eventual formula is chosen while considering it more important to avoid error in predicting the 3-0 victory, which clearly shows a decisive win, than the 1-0 victory, which could easily have come with a heavier reliance on luck.
The third change is brand new and only affects MLS matches, as this is the only source of roster data I have obtained. As the model uses the club (i.e. the Philadelphia Union) as a predictive variable, we now weight the previous match data feeding the model based upon how similar the on-field-players were to the ones currently contributing on-field. Therefore, if a club’s roster is drastically turned over in the off-season, it is no longer as justifiable to use their previous match data in determining their competitive expectations than for a club whose roster was largely untouched. For example, the following shows the “current” Philadelphia baseline of minutes played. This isn’t straightforward counting, as it is weighted based upon how recently the match occurred (and therefore will change rapidly as the 2017 season progresses), but it is what the model is currently viewing as the “Philadelphia Union” roster for its predictive influence. The second column is the percentage of the club’s minutes to be consumed by the player:
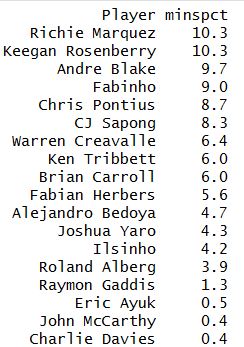
As the season progresses, these baselines for each club will evolve too, as we see Haris Medunjanin, Jay Simpson, Fafa Picault, and the other off-season acquisitions play. And as they do, matches without them will begin to become even less important.
As the season progresses, I hope to do more with the roster information in a way that can better predict a club’s performance.
Enough with the technical jargon, on to the risk-averse forecasts!
Power Rankings
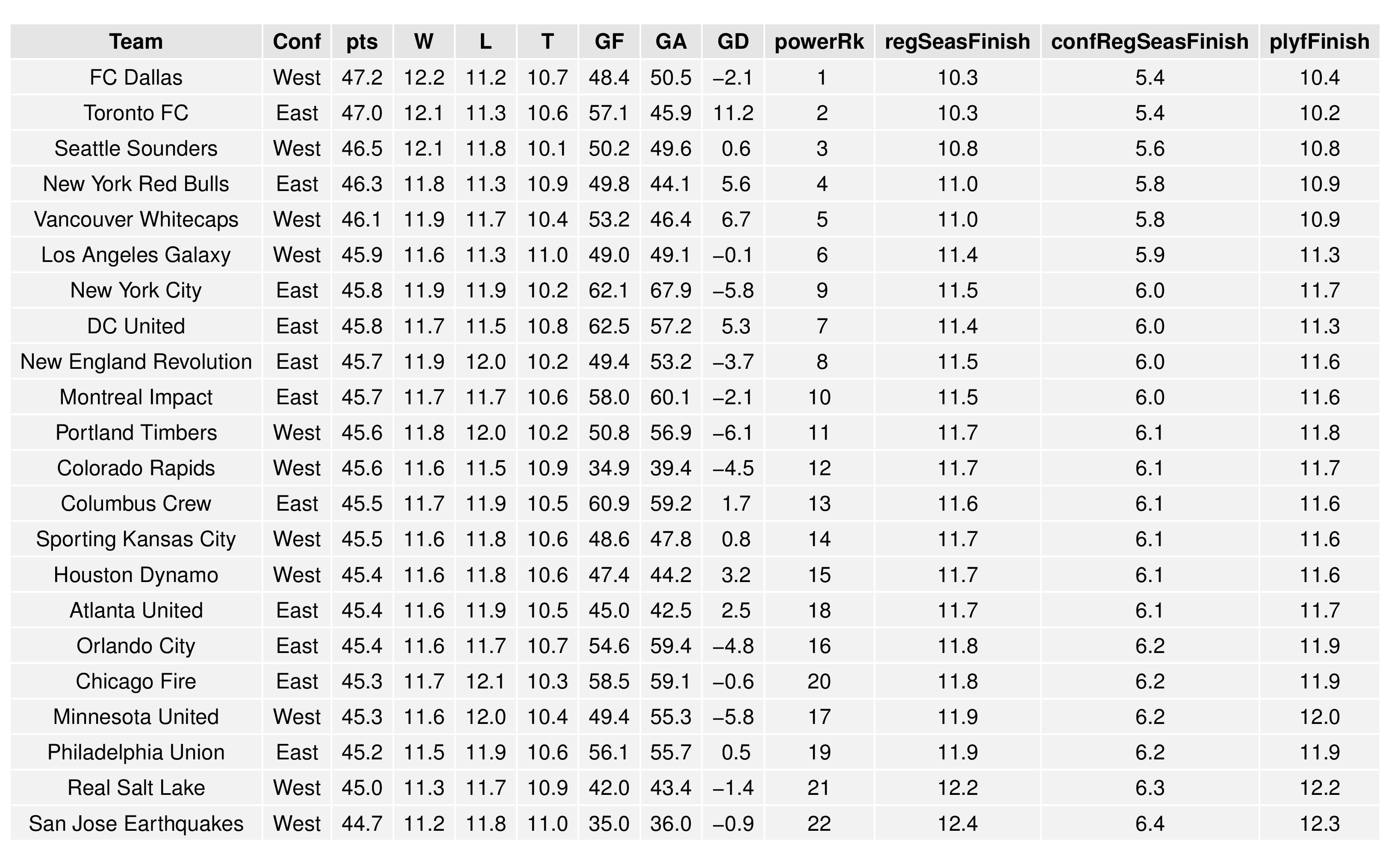
The “Power Rankings” we concoct are the actual “strength” of the team according to competitive expectations. They are computed showing average expected points result if every team in MLS played every team both home and away.
SEBA has the Union at 19th (I don’t actually see them anywhere near that low, as SEBA doesn’t get to see how the Union do better rested and with their off-season additions).
MLSSoccer.com has Philadelphia in 12th, and ESPN has the Union in 13th.
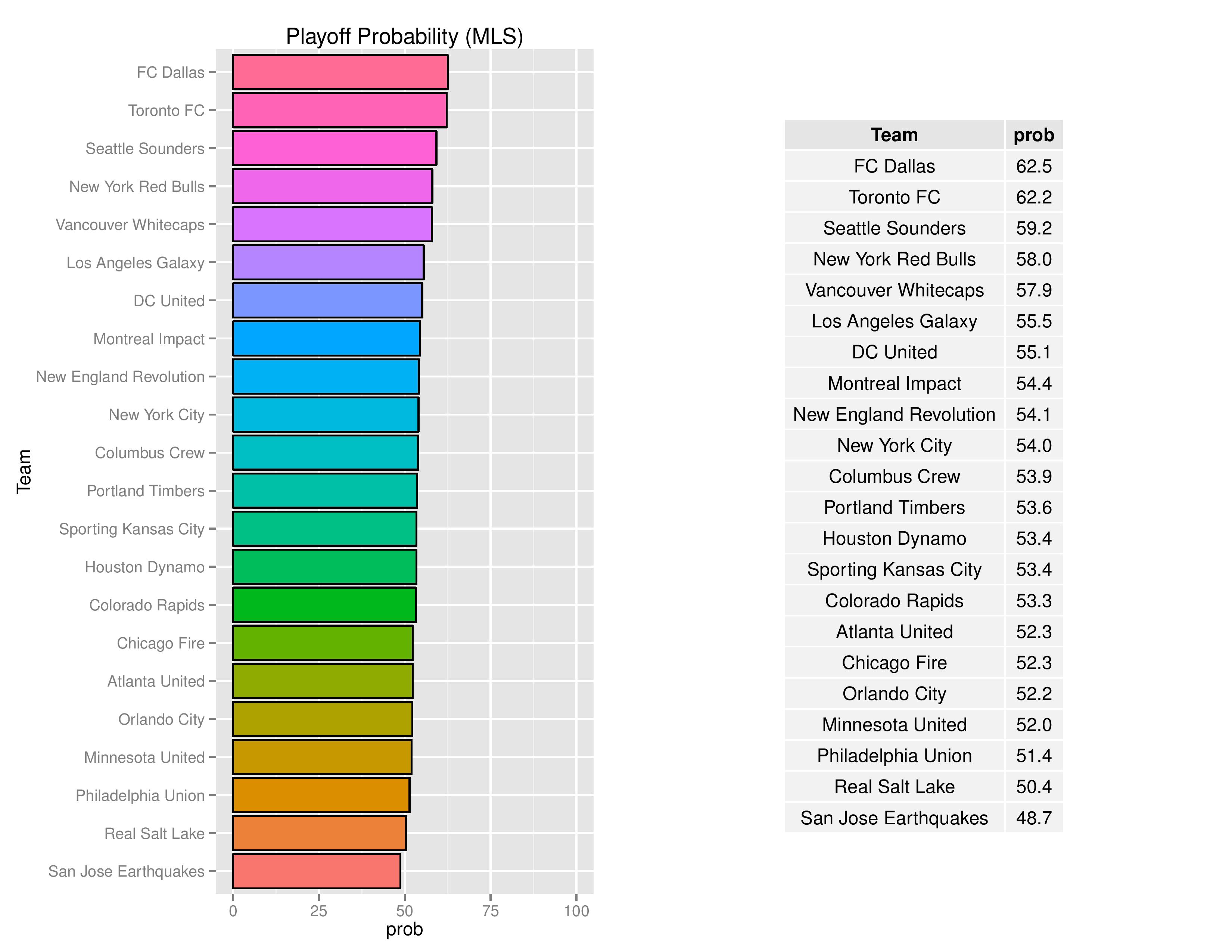
Playoffs probability and more
As 54.5% of teams make the playoffs in MLS with the addition of Atlanta and Minnesota, the Union are marked slightly lower than that at a 51.4% probability of making the playoffs. Again, this is not likely to remain, in my opinion, but is largely based upon matches at the end of last season.
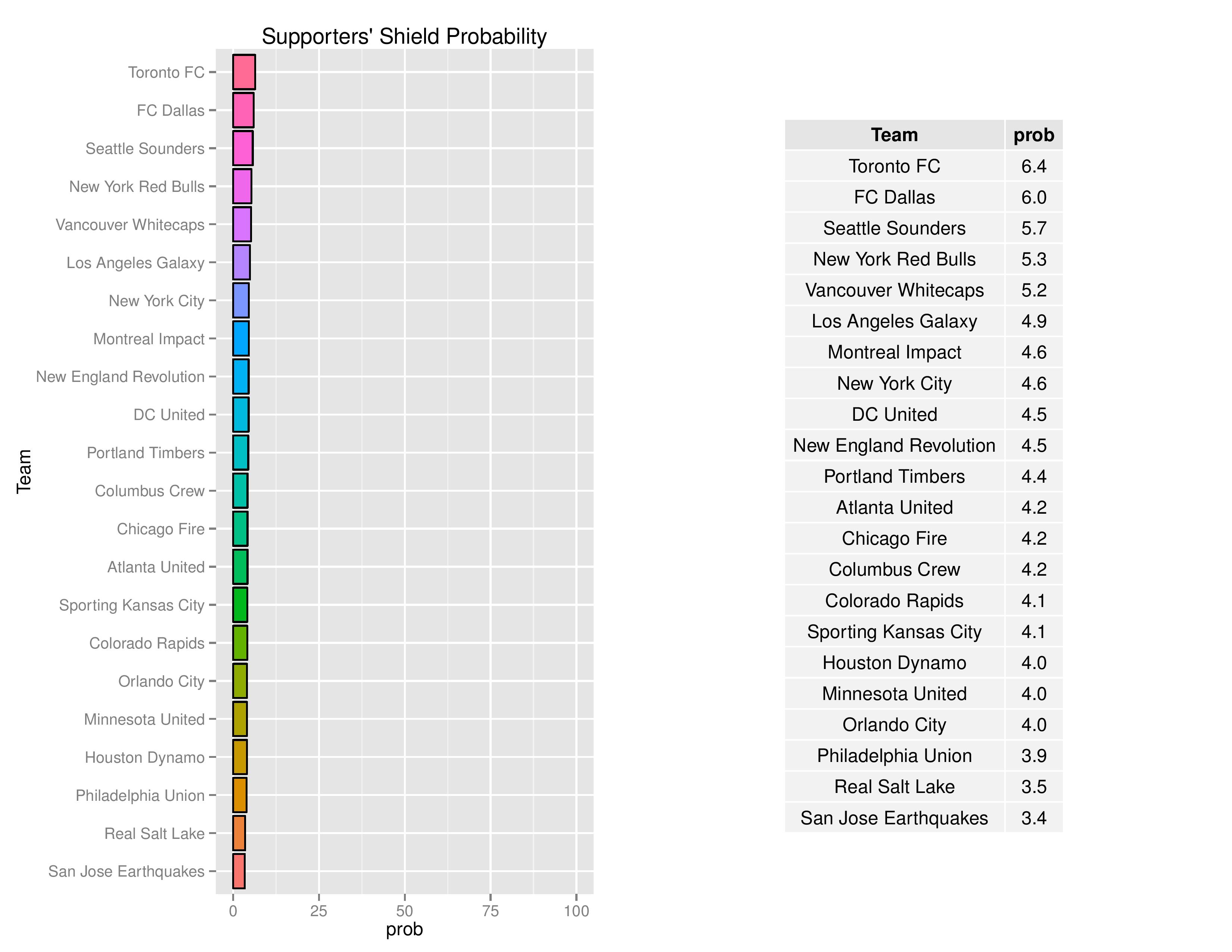
Philadelphia is started off being given a 3.9% chance of winning the Supporters’ Shield.
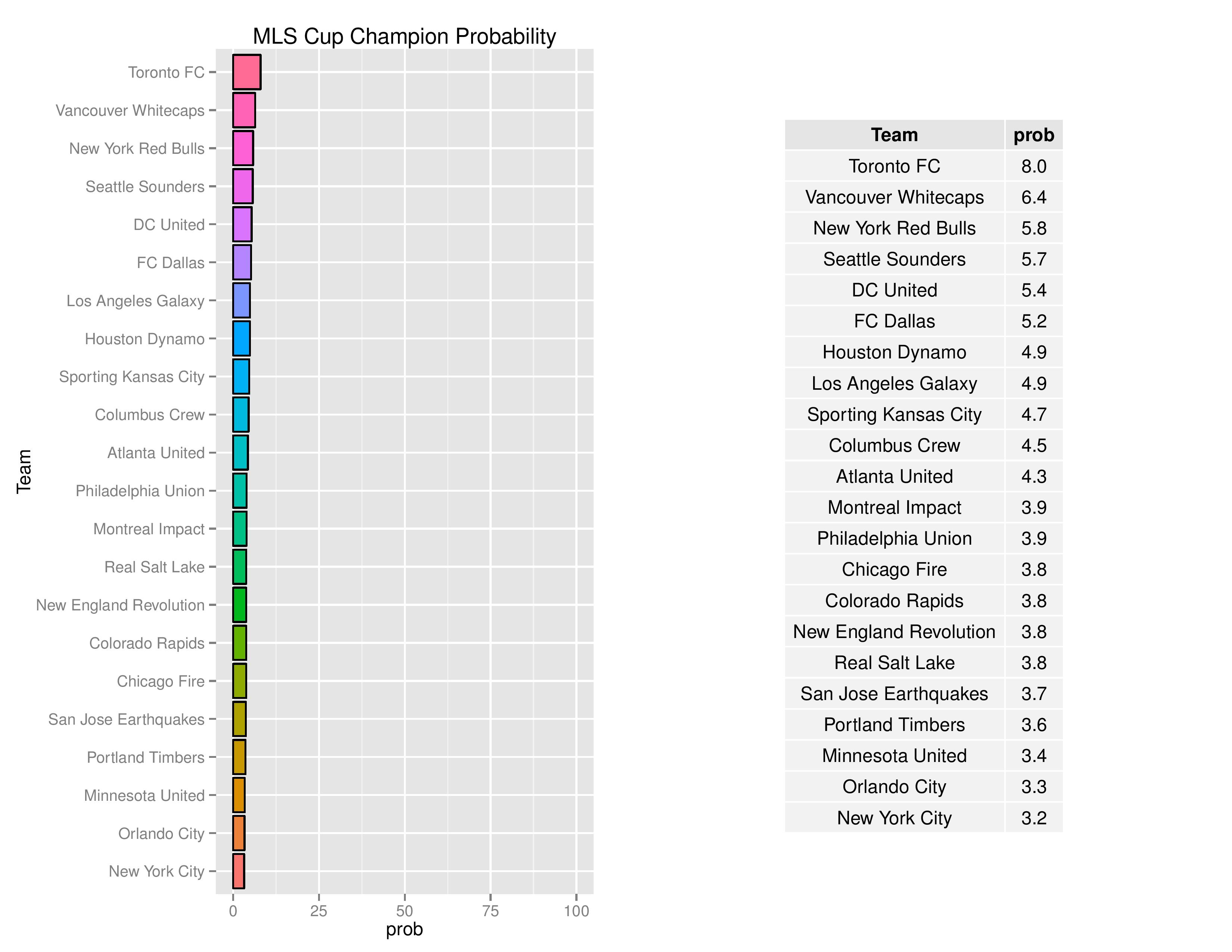
The Union also have a 3.9% chance of winning the MLS Cup.
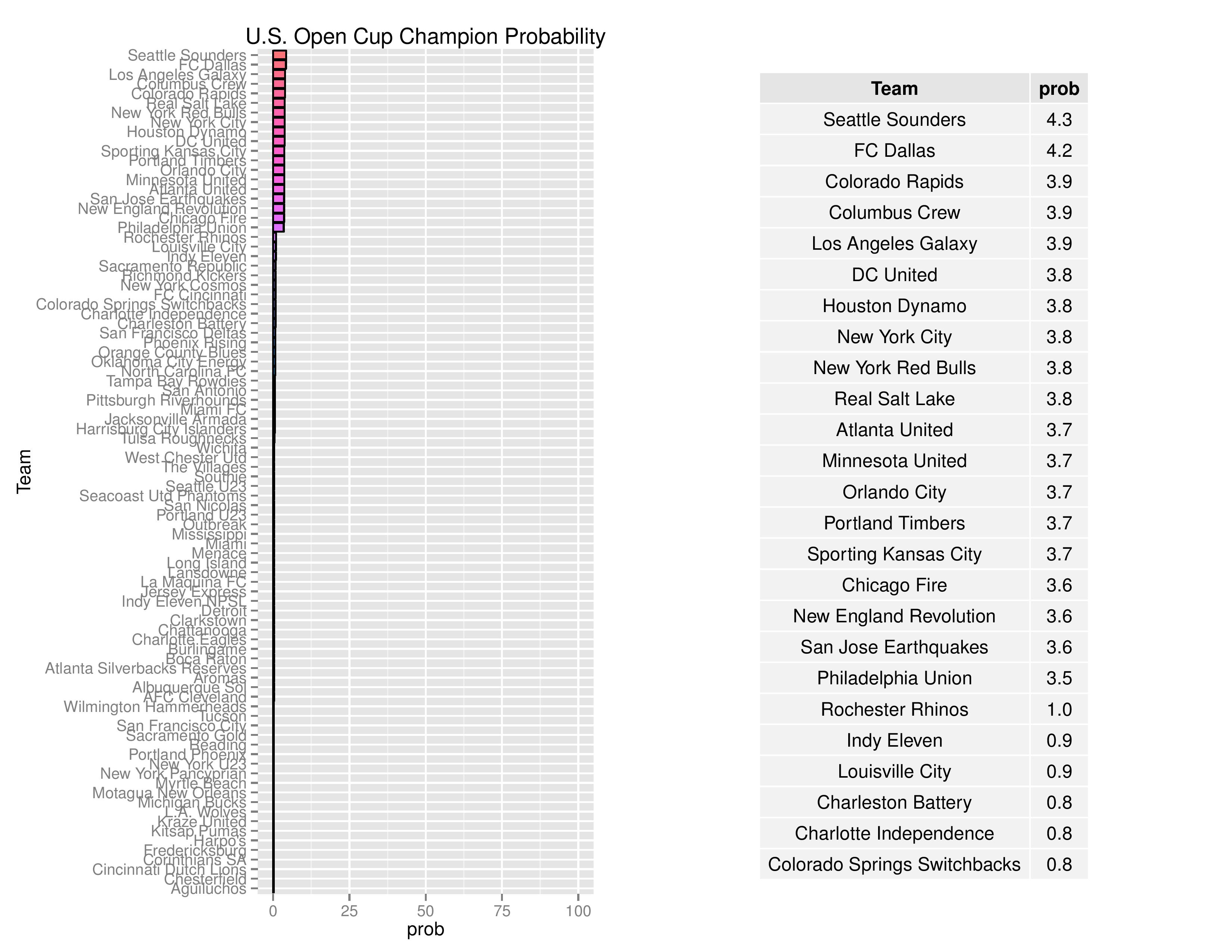
The 2017 US Open Cup’s format hasn’t yet been announced (as of the initial writing/run-of-model), so I had to make some assumptions on the format. I’m assuming that the 22 (by my count) non-MLS-affiliated USL and NASL teams will enter the tournament together, combined with 30 lower-division clubs qualifying from previous rounds with a resulting 13 winners emerging. I’m then assuming the 19 non-Canadian MLS clubs will join the round, culminating in 16 winners, and going on to a regular single-elimination tournament thereafter. As with last year, I have not yet factored in the principle that opponents are chosen based upon geographical proximity rather than randomness. Additionally, as we don’t know which sub-Division-2 teams will qualify for the USOC, I am currently taking a random sample (for each simulation) of qualified, sub-USL clubs from last year’s tournament as proxies.
Philadelphia is currently marked as having a U.S. Open Cup win probability of 3.5%.
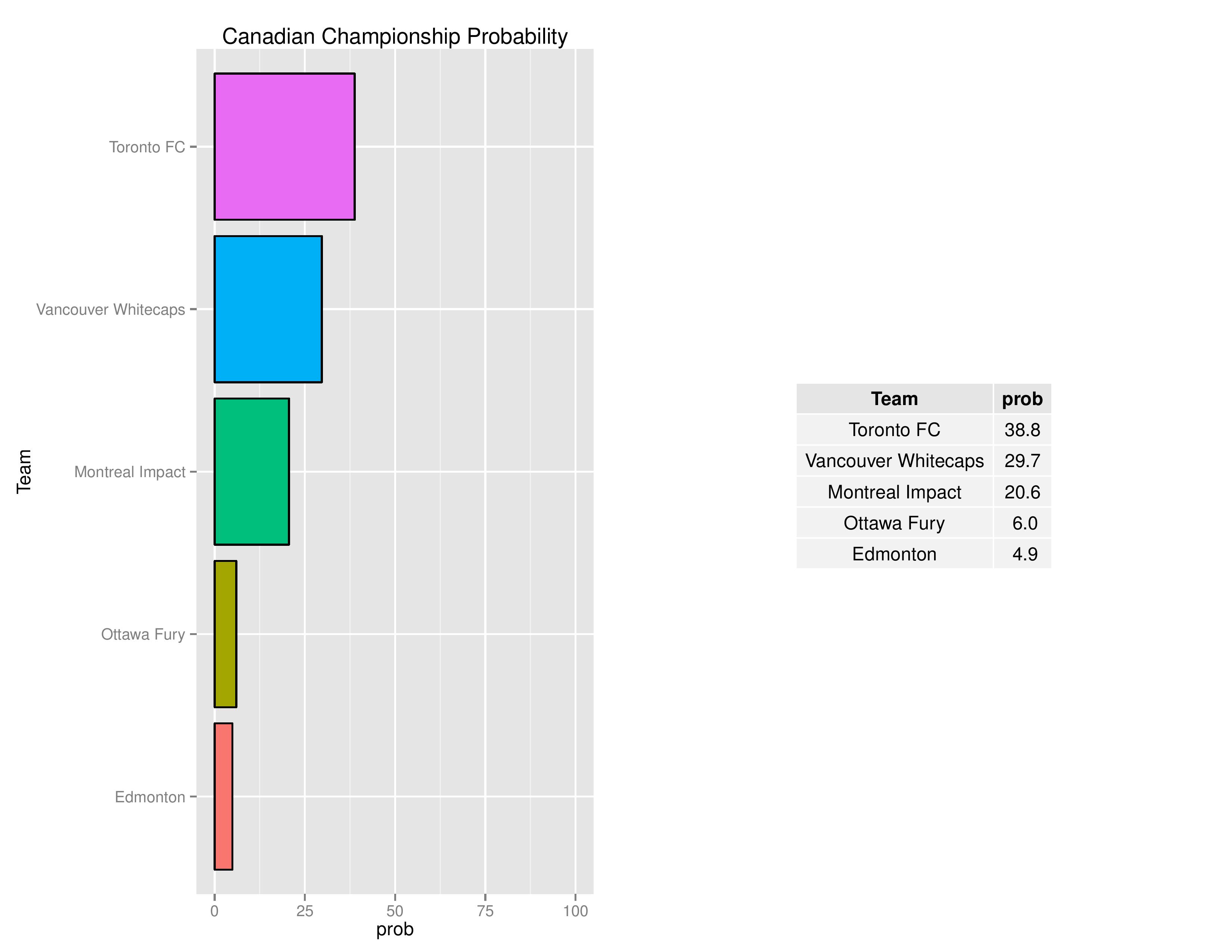
Philadelphia is presently listed as having an 18.0% chance of qualifying for the 2018-2019 edition of the CONCACAF Champions League.

The following are the probabilities of each category of outcomes for Philadelphia.
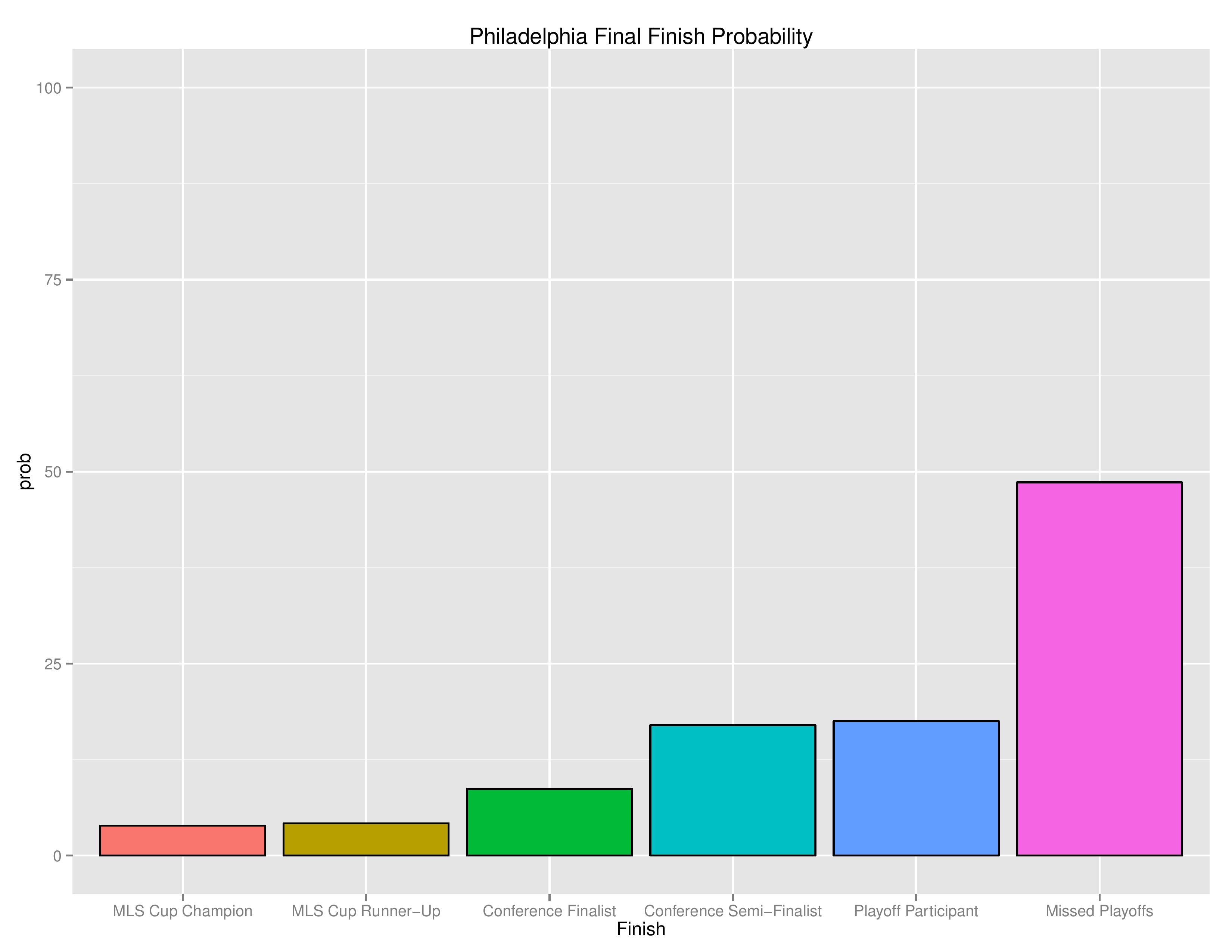
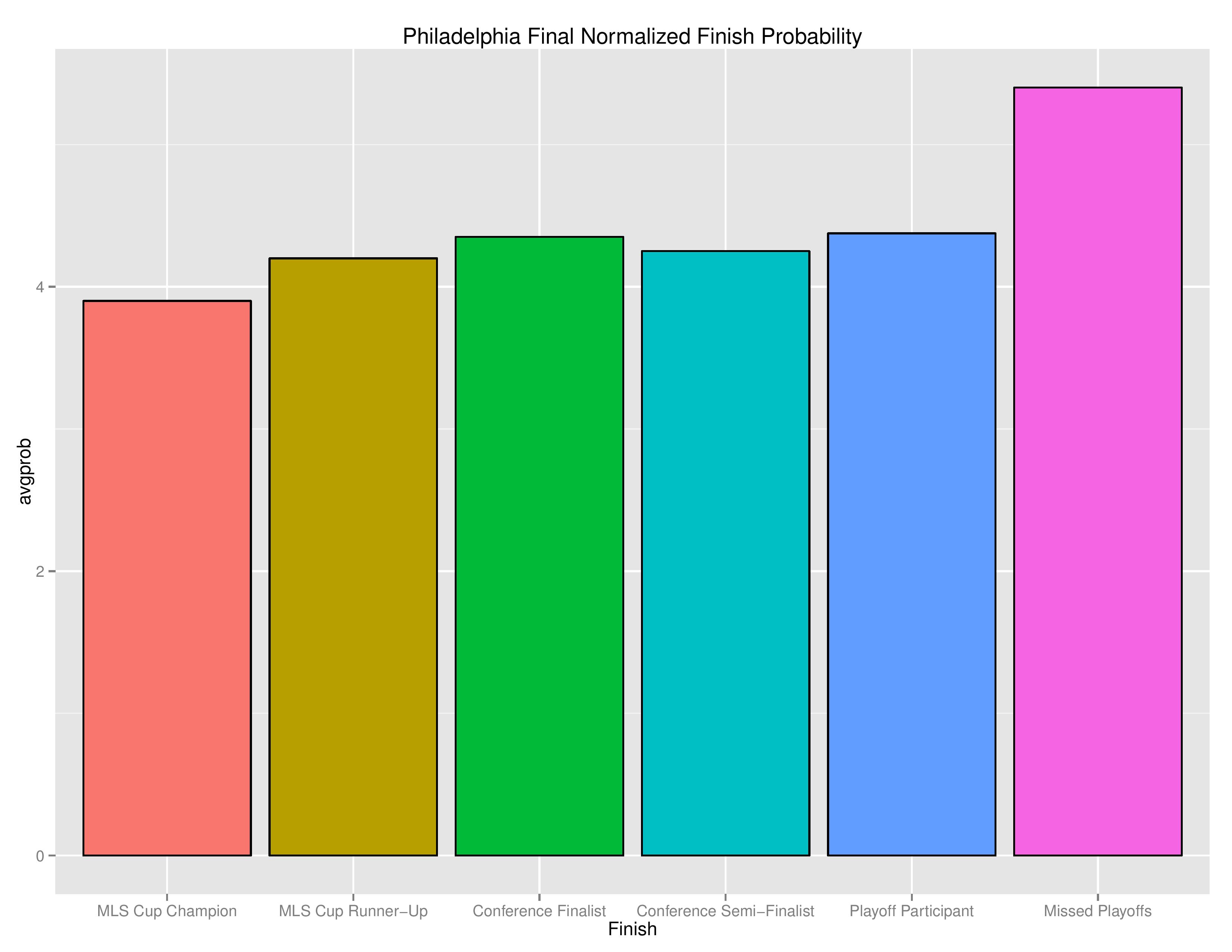
The following shows the relative probability of the prior categories. If the projection system was entirely random, these bars would be even, despite that “Missed Playoffs” is inherently 10 times as likely as “MLS Cup Champion.” This gives a sense of which direction the club is pushing towards.
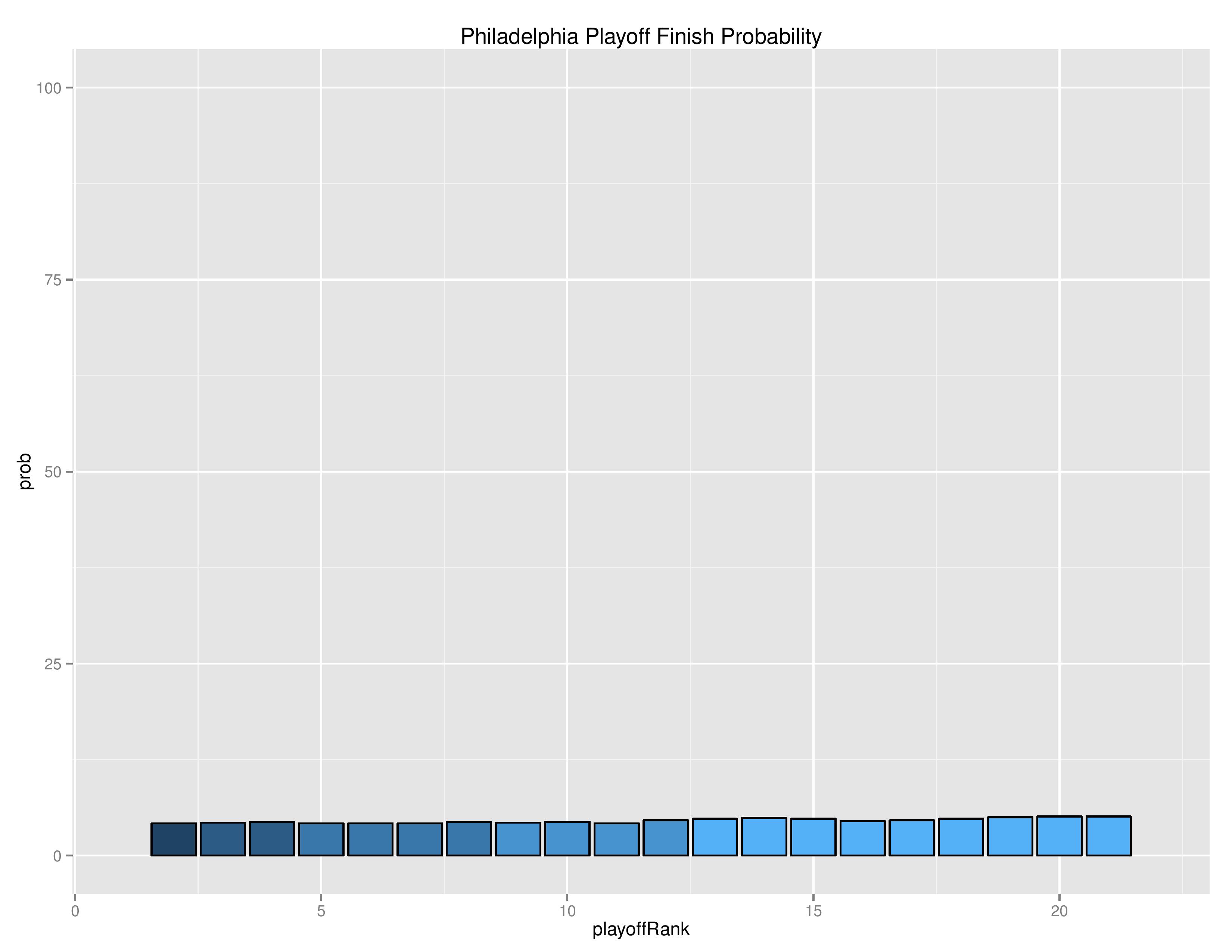
The following shows the probability of each, individual, ranking finish.
The following shows the summary of the simulations in an easy table format.

The following shows the expectations for upcoming Philadelphia matches:
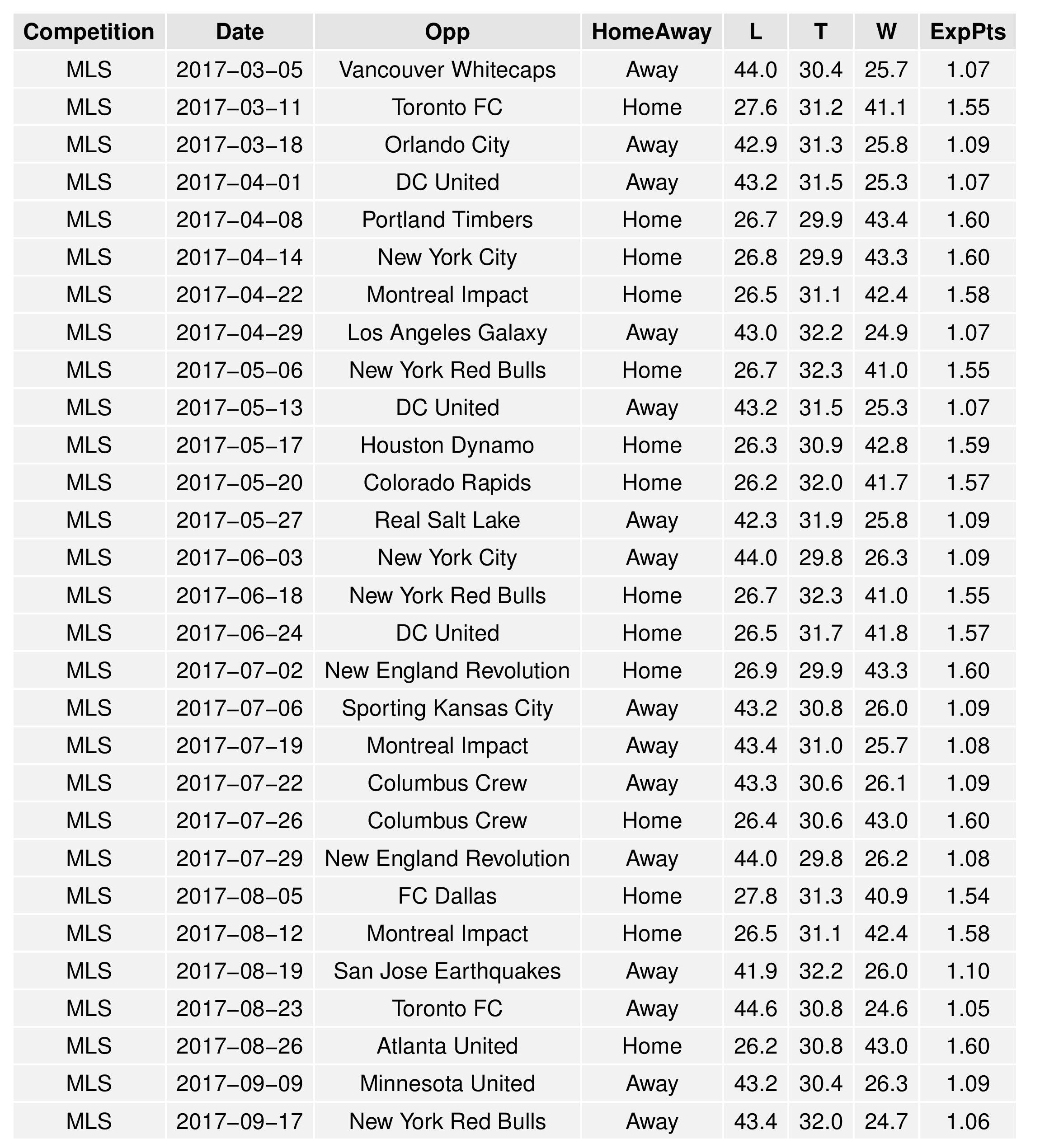
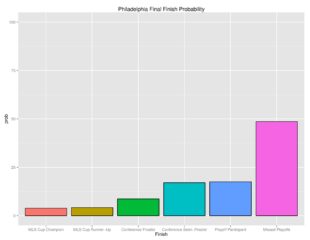

Looking forward to another year of these stats. It does show the Union have a potentially brutal first month with 3 of 4 on the road and 3 of 4 against top 7 teams.
.
One small quibble is that I believe the MLS teams for the 2017-18 CCL have already been set and the Union are trying to qualify for the 2018-19 version.
Good catch, corrected!
Great explanations of how this works. Thank you for your work on this!
The Open Cup is a tough one to judge accurately without getting into some crazy math. There are a lot of small teams in the Midwest and East Coast. You’ll never see the Union matched up against an MLS team in the 4th round like Seattle and Portland were last year.
.
Similarly, with a lot of NASL and USL teams close to Chicago they will normally have a very easy path.
Very interesting. Thanks for pointing this out, as now wanting to test that hypothesis has caused me to move it up the priority list of to-do’s.
Thanks for explaining the model a bit. I was wondering last year how it simulated each game so many times. Did I miss how you come up with the win/loss/draw %s? (if you don’t want to disclose that, that’s ok too)
.
It’s interesting that your model predicts Dallas to finish at the top of the MLS table with a negative goal differential.
.
If your simulation is just determining win/loss/draw by what bin a random number falls into, how does it come up with goal differential?
.
I like how you’re weighing past results by player minutes. Where are you getting the player minutes data? (I’m assuming you aren’t compiling it by hand) Would it be possible to make a +/- per 90 stat for each player?
I don’t want to seem like I’m questioning your model, I’m just interested in how it’s calculated.
haha, no you’re fine JB.
–
I have not have communicated well on the simulations. There is a model that determines the win/loss/draw% for each match. Each match, for each simulation, then chooses a random number between 0 and 1. How that the number relates to win/loss/draw classifications depends on the model’s win/loss/draw percentages (which is the same for all simulations of the same match). This is the same as last year (other than the changes that went into the model).
–
Yes, that is odd, with FC Dallas having a negative GD in first. That is obviously not a likely outcome. Since writing this, I have actually made an adjustment to the score-estimating models to get better score projections. The new weighting schemes likely messed with the Goals forecasts in a way I didn’t intend. The new weights favor high-scoring affairs, so it is likely producing more wacky predictions. The change no longer employs the weighting system for the score-estimating models.
–
As I alluded to above, after the initial win/draw/loss model, there is an additional Goal Differential and a Goals Scored model to predict the score. In this case, the model predicts a mean/variance for a normal distribution of the predicted outcome, and a random number is selected from within that probability distribution (and then rounded to the nearest whole number that makes sense, i.e., can’t have 0 goals for a win). The purpose of this is just to have a reasonable source for tiebreakers.
–
I thought about doing a +/-, but I need to find a source of when goals occur to derive it (and figure out how to deal with ties, such as if both a substitution and a goal both occurred in the 78th minute, was the sub on the field or off?)
Is any of this on Github? I’m trying to teach myself data science, and I’d live to see some of this.